
Tempo de leitura: 7 minutos
Localizar e substituir texto no Notepad++ usando Regex – Expressão Regular
Índice
- Alguns detalhes que você deve cuidar para utilizar a ferramenta Notepad++
- Removendo espaços em branco
- Insira uma nova linha para cada linha de texto
- Removendo linhas em branco
- Quebrar a lista separada por vírgula em linha
- Remova palavras duplicadas
- Deixar apenas a primeira palavra de cada linha
- Deixar apenas a última palavra de cada linha
- Substitua todas as linhas duplicadas por uma única linha
- Insira todo o texto em uma única linha
- Substitua a primeira linha no texto
- Remova caracteres indesejados
- Converter palavras para minúscula, exceto para siglas e abreviações
- Como fazer uma expressão regular que ache um nome e depois procure um caractere?
Neste artigo vamos tentar passar algumas dicas de como usar Expressão Regular usando Notepad ++. No dia a dia é muito comum para desenvolvedores fazerem modificações em massa, a acaba sempre usando a ferramenta de forma manual. Nosso objetivo é torna mais fácil e rápido as alterações.
Alguns detalhes que você deve cuidar para utilizar a ferramenta Notepad++
Em todos os exemplos, use Localizar e substituir (Ctrl + H) para substituir todas as correspondências pela string desejada ou (sem string).
Certifique-se de que o botão de opção ‘Expressão regular’ esteja definido.
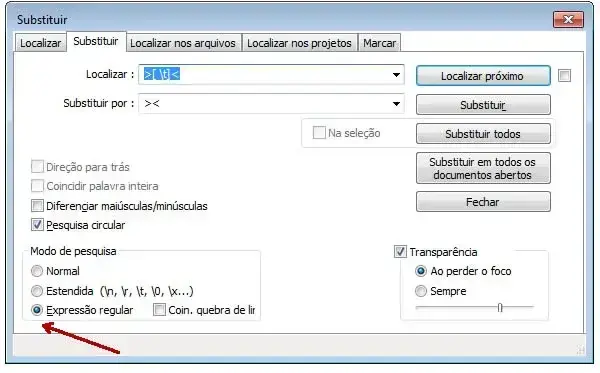
Removendo espaços em branco
Como remover no notepad++ espaços em branco nos textos e códigos. Neste exemplo, substituímos os espaços em branco e as guias entre os pares de strings "> <"
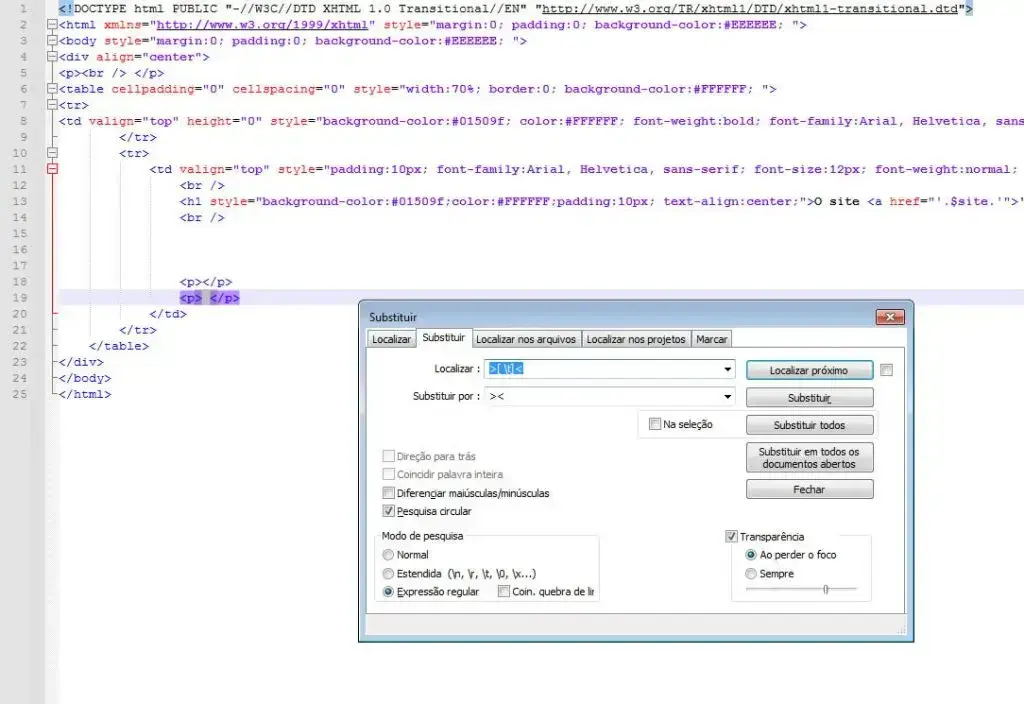
Veja o texto de Expressão Regular: https://rubular.com/r/GKTqfI34My78LT
Expressão de correspondência Regex: (Desative a quebra de linha para que você possa vê-la mesclada em uma linha)
>[ \t]<
No campo Substituir use:
><
Insira uma nova linha para cada linha de texto
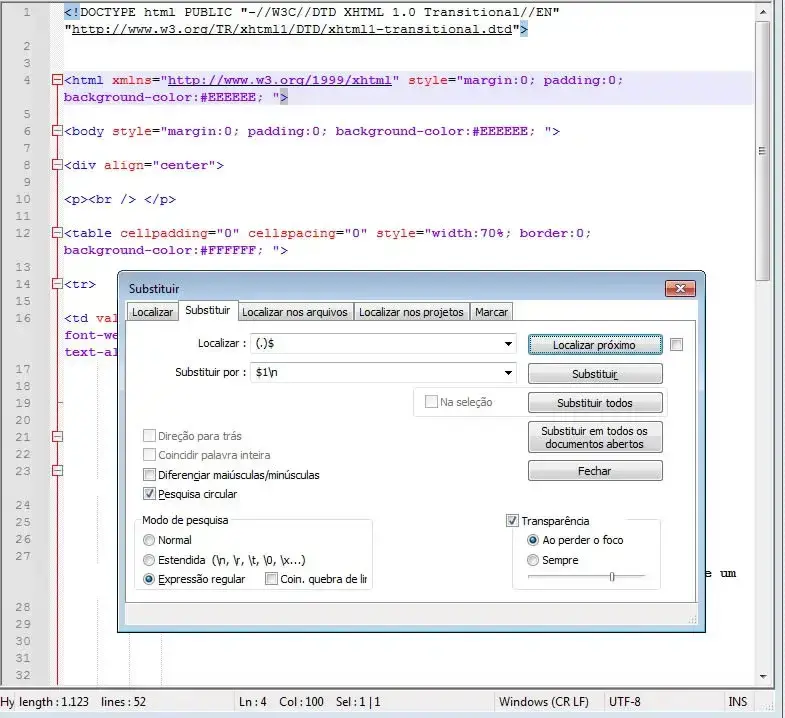
Veja o teste na expressão regular: https://rubular.com/r/VSwfp0CvIV4RJO
Campo Localizar:
(.)$
Campo Substituir:
$1\n
Removendo linhas em branco
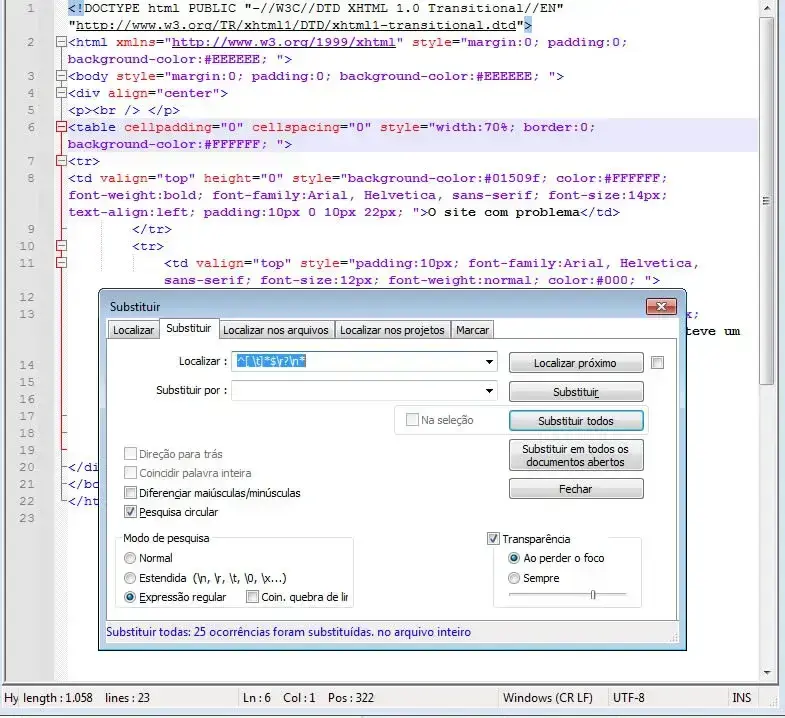
Veja o teste na expressão regular: https://rubular.com/r/q09H3O3TBSKbWo
Campo Localizar:
^[ \t]*$\r?\n*
Campo Substituir: Deixe vazio.
Quebrar a lista separada por vírgula em linha
Substitua a lista separada por vírgulas pela lista de strings
Veja o teste de expressão regular: https://rubular.com/r/puQ3XgV9Zjvyrl
Campo Localizar:
,[ \t]+
Campo Substituir:
\n
Continua após a publicidade
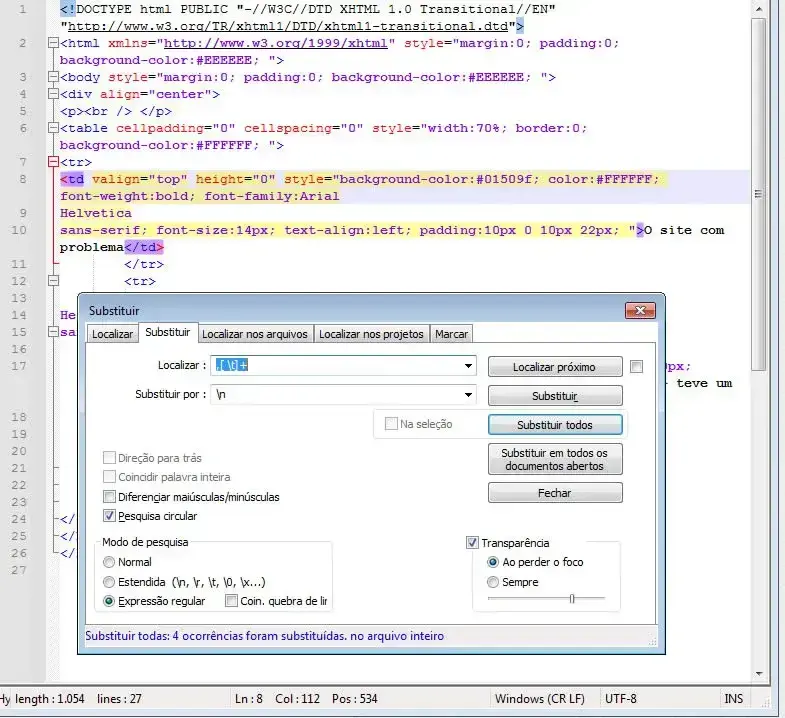
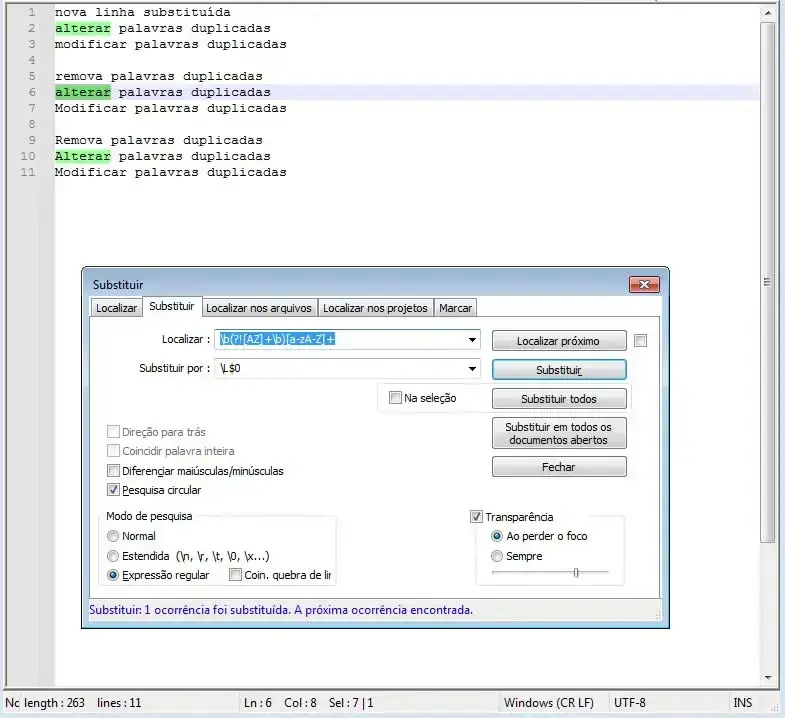
Remova palavras duplicadas
Campo Localizar:
\b(\w+)\s+\1\b
Campo Substituir:
\1
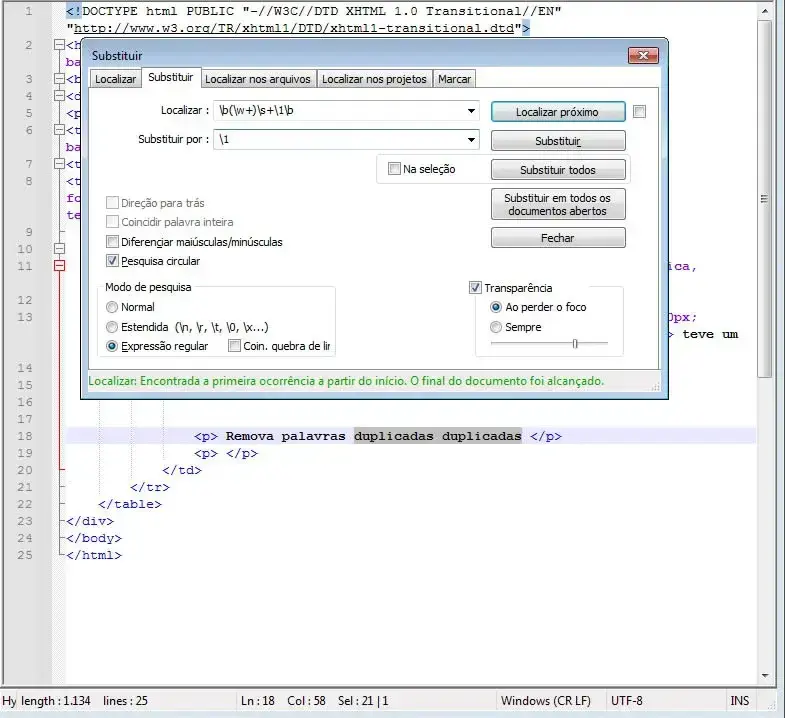
Deixar apenas a primeira palavra de cada linha
Campo Localizar:
^([^ \t]+).*
Campo Substituir:
\1
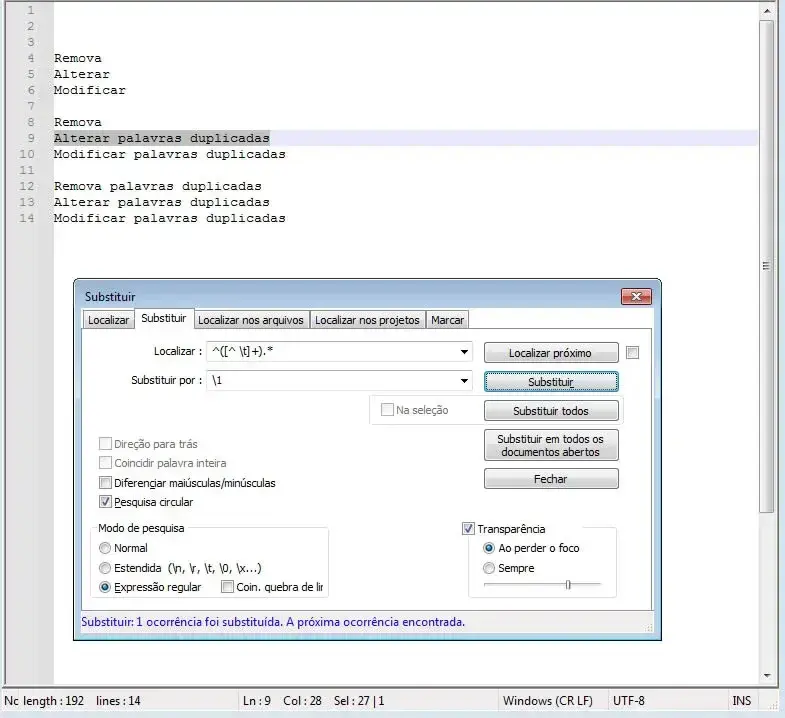
Deixar apenas a última palavra de cada linha
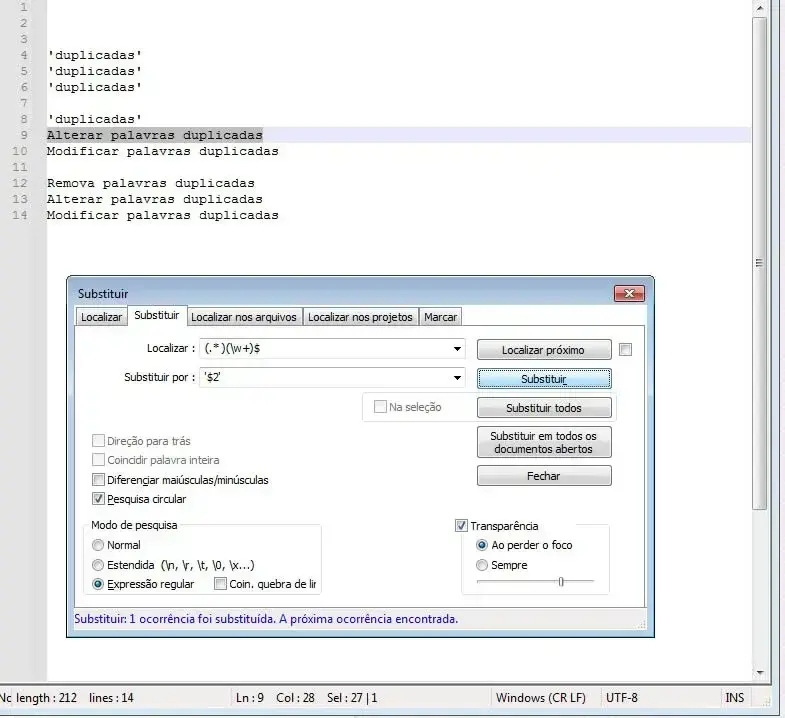
Neste exemplo deixamos apenas a última palavra e colocamos entre aspas. bastas tirar as aspas no código do campo Substituir se não for necessário.
Campo Localizar:
(.* )(\w+)$
Campo Substituir:
'$2'
Substitua todas as linhas duplicadas por uma única linha
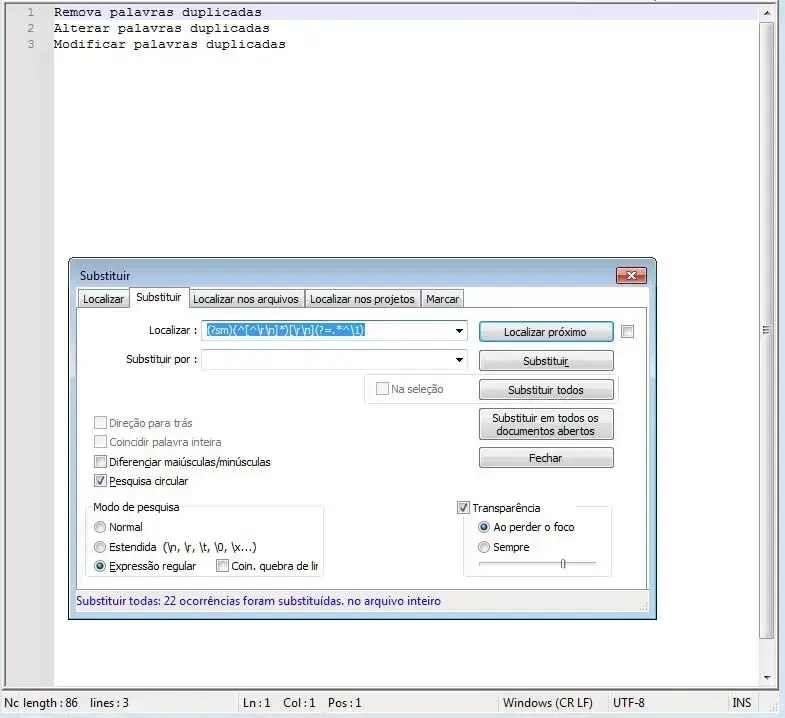
Campo Localizar:
(?sm)(^[^\r\n]*)[\r\n](?=.*^\1)
Campo Substituir:
Deixar vazio.
Insira todo o texto em uma única linha
Para quem gostaria de ** minificar ** o HTML usando o Notepad++ esta é uma grande dica de uso:
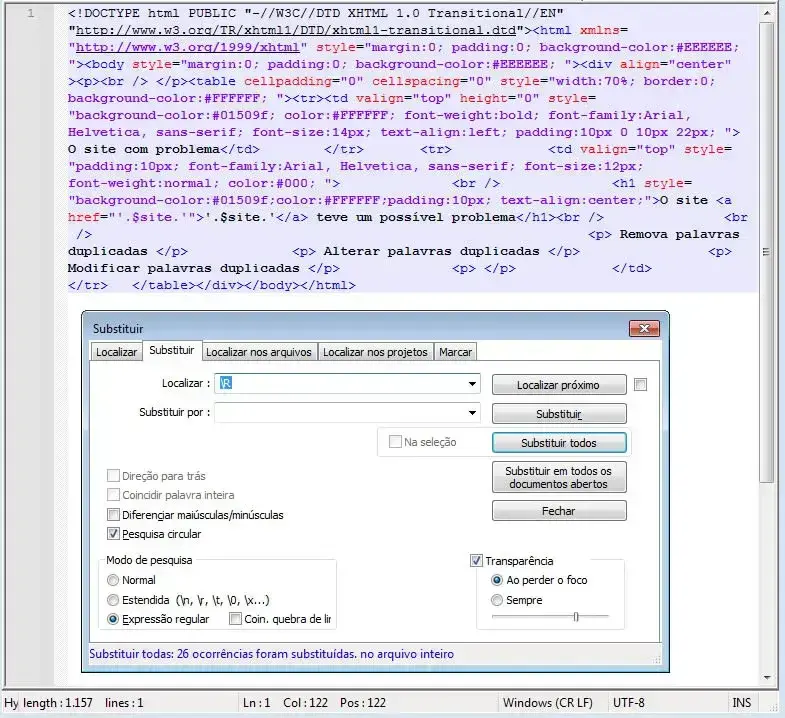
Depois de executado você pode usar o item 3 para limpar os espaços em excesso.
Campo Localizar:
\R
Campo Substituir: Deixar vazio.
Substitua a primeira linha no texto
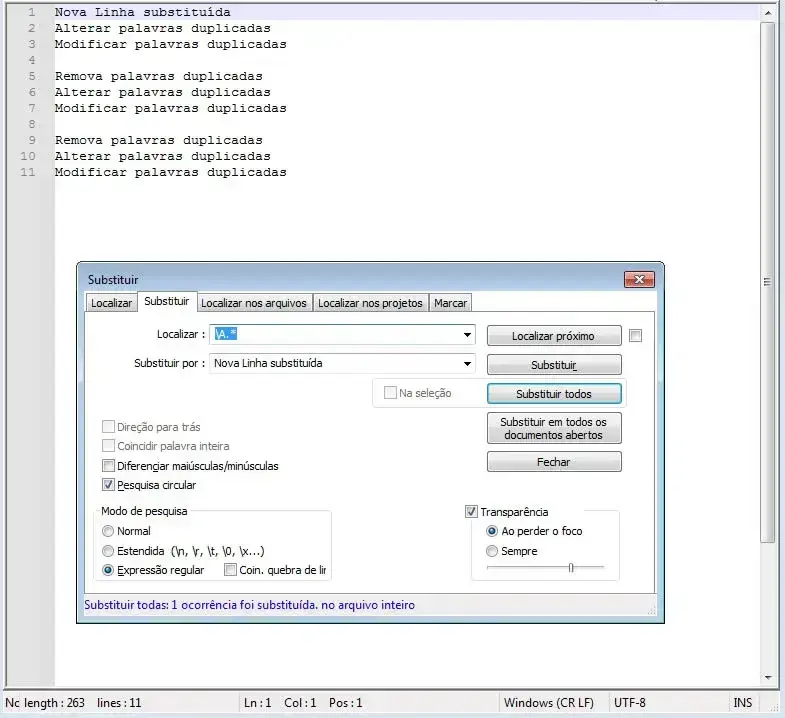
Campo Localizar:
\A.*
Campo Substituir: Deixar vazio.
Remova caracteres indesejados
Podemos querer remover todos os caracteres especiais e deixar letras e números. Para caracteres alfanuméricos, pontos finais, dois pontos/ponto, vírgula, espaços, tabulações, novas linhas, é melhor você testar antes de executar, utilize esta ferramenta:
https://rubular.com/r/QRJaEtXtNwlKZP
Nela tentei retirar apenas os caracteres < e > Utilizei o escape contra barra \ para não pegar os caracteres que eu não queria retirar do código
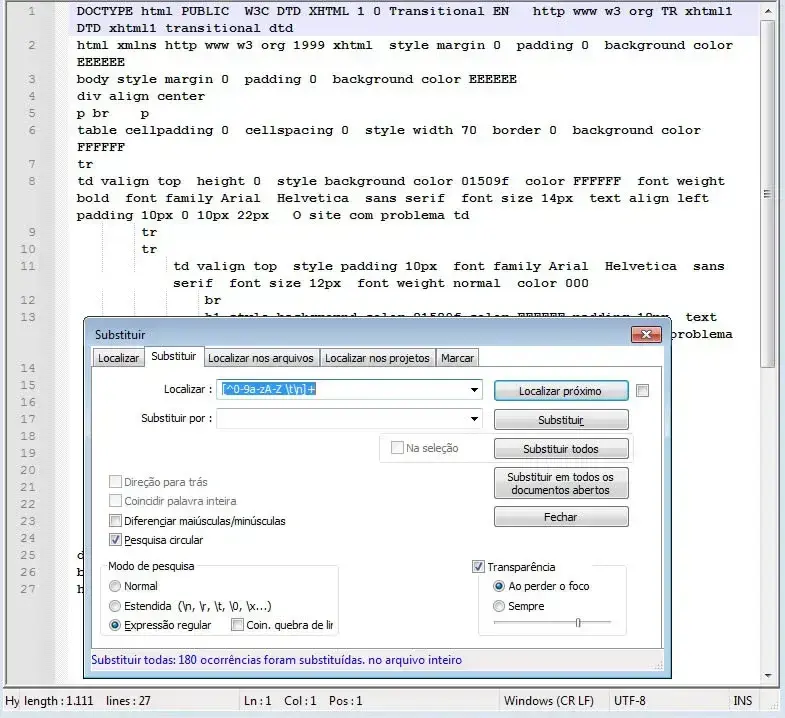
Campo Localizar:
[^0-9a-zA-Z \t\n]+
Campo Substituir: (Digite a tecla espaço para não deixar as palavras juntas)
Converter palavras para minúscula, exceto para siglas e abreviações
Podemos querer garantir que o texto seja convertido em letras minúsculas, exceto para acrônimos e abreviaturas que são mantidos em letras maiúsculas.
Campo Localizar:
\b(?![AZ]+\b)[a-zA-Z]+
Campo Substituir:
\L$0
Entenda alguns caracteres usados na Expressão Regular:
\n quebra de linha
\t Tab
\d Um dígito no intervalo de 0-9 (um número)
\D Não é um dígito. Qualquer coisa que não seja um número (incluindo espaços).
\l Uma letra minúscula. OBSERVAÇÃO: isso retornará a “um caractere de palavra” se a opção de pesquisa “Match case” estiver desativada.
\L Não é uma letra minúscula.
\u Uma letra maiúscula.
\U Não é uma letra maiúscula.
\w Um caractere de palavra, que é uma letra, dígito ou sublinhado. Isso parece não depender do que o componente Scintilla considera como caracteres de palavras. O mesmo que [[:palavra:]].
\W Não é um caractere de palavra.
\s Um caractere de espaçamento: contagem de espaço, EOLs e tabulações.
\S Não é um espaço.
\h Espaçamento horizontal. Isso corresponde apenas ao espaço, tabulação e alimentação de linha.
\H Não é espaço em branco horizontal.
\v Espaço em branco vertical.
\V Não é espaço em branco vertical
$ Aplica-se apenas ao caractere no final de uma linha. (ex. !$ substituiria todos os pontos de explicação no final de uma linha.)
^ Online aplica-se ao caractere no início de uma linha (ex. ^<p> substituiria qualquer <p> no início de uma linha.)
Como fazer uma expressão regular que ache um nome e depois procure um caractere?
Suponhamos que temos um código html que contém basicamente este formato:
<span id="mensagem" class="topo">Classes e comandos</span>
Imagine se a quantidade de argumentos dentro da tag <span> variar de quantidade de caracteres e posição destes caracteres
Como podemos obter o conjunto “Classes e comandos”?
Para isso, preciso que quando a busca ache a sequência “mensagem”, procure o próximo caractere > e, quando achar, pegue a sequência de caracteres à frente que forem diferentes do caractere <.
É isso que queremos:

Vá para Pesquisar-> Substituir.
Defina o valor do campo Pesquisar/Localizar: (<.*?(?=mensagem).*?>)(.*?)(<.*?>)|(.*)
Defina o valor do campo Substituir com: \2 ou $2.
Defina o modo de busca como: Expressão regular.
Clique no botão: Substituir tudo.
Isso vai substituir todo o texto pelos conteúdos que possuem a palavra chave mensagem dentro da tag.
Você pode testar essa regex aqui.
Caso não tenha resolvido o seu problema comente aqui o que esperava, o que aconteceu de errado e tento resolver, espero ter ajudado :D
Explicação da Regex
Essa regex possui 4 grupos de capturas, vou explicar o que cada um faz para que possa entender melhor
(<.*?(?=mensagem).*?>)
O grupo 1 vai capturar tudo que está entre a tag, isso se possuir a palavra mensagem em qualquer posição antes do caractere >, para isso usei um positive lookahead, ele determina que tudo entre (?= e ) é uma condição para captura do que está antes.
(.*?)
O grupo 2 só será acionado caso o grupo 1 capture algo, já que está na mesma expressão e não está depois de um operador OU, ele captura tudo menos quebras de linhas e para assim que outro caractere da expressão seguinte for encontrado.
(<.*?>)
O grupo 3 captura tudo que está entre as tags após o grupo 2, a tag < também serve como um limitador para que o grupo 2 pare de capturar quando encontra-lo.
|(.*)
O grupo 4 é uma expressão que está depois do operador OU, isso significa que caso a regex não capture com a expressão anterior, irá tentar capturar com essa, logo só inseri um operador “.” para capturar qualquer caractere que não seja quebra de linha (\n), então tudo que não corresponder com sua pesquisa irá ser apagado ao substituir tudo pelos conteúdos do grupo 2.
Siga os passos:
Vá para Pesquisar -> Substituir.
Defina o valor do campo Pesquisar/Localizar com: <span[^>]+>(.*?)</span>
Defina o valor do campo Substituir com: \1 ou \2.
Defina o modo de busca como: Expressão regular.
Clique no botão: Substituir tudo.
Lembrando que ele vai deixar apenas o resultado encontrado, exemplo:
<div>
<span id="mensagem" class="topo">Texto 01</span>
<span id="mensagem" class="topo">Texto 02</span>
<span id="mensagem" class="topo">Texto 03</span>
<span id="mensagem" class="topo">Texto 04</span>
<span id="mensagem" class="topo">Texto 05</span>
</div>
Ao aplicar o regex fica apenas:
Texto 01
Texto 02
Texto 03
Texto 04
Texto 05
Para entender mais sobre o assunto:
https://aurelio.net/regex/npp/
Um ótimo livro: Expressões Regulares - Uma abordagem divertida
Publicidade
📢 Quer ficar por dentro de todas as novidades do nosso blog? Não perca os últimos artigos, dicas valiosas e informações relevantes!
Junte-se a nós nas redes sociais para receber em primeira mão:
- Artigos exclusivos;
- Dicas práticas;
- Ofertas especiais e descontos exclusivos para nossos seguidores.
Não vamos inundar sua caixa de entrada com newsletters! Simplesmente nos siga em uma de nossas redes sociais para garantir que você não perca nenhum conteúdo interessante. Estamos ansiosos para tê-lo(a) conosco! 🚀
ANÚNCIOS


Cinco Unidades em
Petrópolis, Rio de Janeiro
Unidade Quitandinha:
Rua General Rondon, 170 – Ao lado do Supermercado Bramil
(24) 2020-6837
Unidade Centro:
Rua Aureliano Coutinho, 67 – Centro – Serra Shopping
(24) 2020-6837
Unidade Bingen:
Rua Bingen, 2145 – Bingen (em frente ao Bob’s) (24) 2006-0046
Unidade Itaipava:
Estrada União e Indústria, 11.881 – G2 (Bramil Itaipava) (24) 2232-1369
Unidade Itamarati:
Rua Bernardo Proença, 156 – loja 01 (Bramil Itamarati) (24) 2249-3611